Aerospike
Kontrolle nach Bedarf.
Sicherheit als Standard.
Ein Cluster-Provisioning-Flow, der Teams ermöglicht, mit sicheren Standards schnell voranzukommen, bei Bedarf auf erweiterte Kontrolle umzuschalten und sich schnell zu erholen, wenn etwas schiefgeht. Entwickelt als erstes Erlebnis, das Aerospike Cloud aus der Preview-Phase in die allgemeine Verfügbarkeit geführt hat.
Unternehmen
Aerospike
Produkt
Managed cloud database platform
Jahr
2025
Rolle
Alleiniger Designer
Umfang
End-to-End-Provisioning-Flow
Zusammenarbeit
Engineering, Produkt, Backend- und Datenbankingenieure
Die Herausforderung
Vor diesem Projekt bedeutete der Einstieg in Aerospike: die Datenbank selbst installieren, die eigene Infrastruktur provisionieren und die Konfiguration aus der Dokumentation herleiten. Für erfahrene Nutzer war das kein Problem. Für alle anderen war es ein Grund, es gar nicht erst zu versuchen.
Aerospike Cloud war das Managed-Angebot, das das ändern sollte. Damit es funktioniert, brauchten Kunden einen Self-Service-Weg zu produktionsbereiten Clustern. Kein Tutorial, keine Preview. Ein zuverlässiges erstes Erlebnis, das von Anfang an Vertrauen weckt.
Managed Services haben einen anderen Anspruch als selbstverwaltete Lösungen. Standardwerte müssen sicher sein. Fehlkonfiguration muss schwer sein. Fehlermeldungen müssen tatsächlich erklären, was schiefgelaufen ist. Und das Ganze muss schnell gehen. Aerospikes Kunden sind Backend-, Plattform- und Operations-Engineers, die ihre Infrastruktur kennen und Präzision erwarten. Ein Flow, der sich vereinfacht oder undurchsichtig anfühlt, verliert sie sofort.
Den Betrieb von Infrastruktur zu ermöglichen war nur ein Teil davon. Der eigentliche Maßstab war, ob ein Team seine Anwendung verbinden und Daten fließen sehen konnte. Alles in derselben Sitzung.
Meine Rolle
Ich war der alleinige Designer des Provisioning-Flows und übernahm dabei auch einen großen Teil der Produkt- und Frontend-Verantwortung. Ich definierte die Gesamtstruktur und die Schrittabfolge, entschied, welche Konfigurationen offengelegt und welche abstrahiert werden sollten, gestaltete die Einführung erweiterter Einstellungen und JSON/YAML, schrieb Tickets, testete Implementierungen und trieb Entscheidungen voran, wenn Verantwortlichkeiten unklar waren.
Ich arbeitete am engsten mit dem Engineering-Manager, Frontend-Engineers und Backend- und Datenbankengineers zusammen. Produkt war durchgehend einbezogen, aber ich trieb oft die Priorisierung voran, um die Dinge in Bewegung zu halten.
Die Engineers, die Aerospike gebaut haben, kannten das Produkt in der Tiefe und wollten, dass die UI das alles widerspiegelt: jede Konfigurationsoption, jeden erweiterten Parameter. Ich musste immer wieder gegensteuern. Meine Einschätzung war, dass echte Power-User eine Web-UI sowieso nicht nutzen würden. Die wären in der API, der CLI, würden direkt mit Configs arbeiten. Die UI musste neue und fortgeschrittene Nutzer gut bedienen, und zu versuchen, die Tiefe der API abzubilden, hätte genau die Menschen begraben, die eigentlich Orientierung brauchten.
Das andere, worauf ich hart gepusht habe, war Terminologie. Aerospike hat seine eigene Sprache. Namespaces, Sets, Records, Bins. Die muss konsistent sein — über UI, APIs, Dokumentation und die Datenbank selbst. Wenn sie es nicht ist, verlieren Nutzer das Vertrauen und die Lernkurve wird steiler. Ich habe viel Zeit damit verbracht, Leute zurückzuholen, wenn Dinge anfingen, anders benannt zu werden.
Die zentrale Spannung
Das eigentliche Problem war nicht, wie man ein Formular baut. Es ging darum, zwei völlig unterschiedliche Erwartungen zu bedienen, ohne das Produkt aufzuspalten oder jemanden auf den falschen Weg zu zwingen.
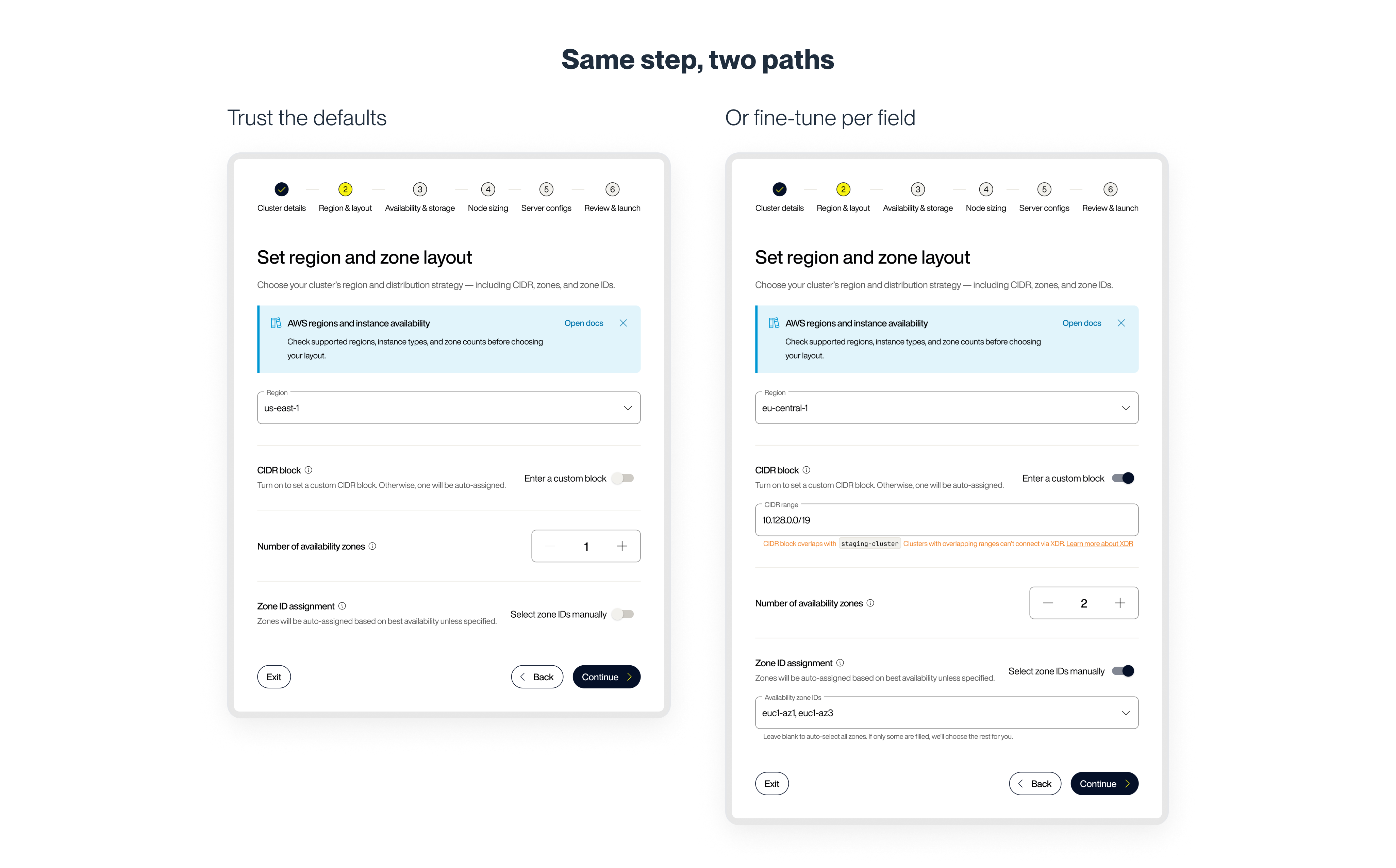
Manche Nutzer wollten schnell vorankommen und dem System vertrauen. Sie waren nicht hier, um Replikationsfaktoren zu justieren – sie wollten einen funktionierenden Cluster. Andere brauchten Transparenz und Kontrolle. Das waren Engineers, die selbstverwaltetes Aerospike in der Produktion betrieben, und die würden das nicht einem Formular mit versteckten Einstellungen überlassen.
Zu einfach gestaltet, und die zweite Gruppe würde es nicht vertrauen. Zu komplex, und die erste Gruppe würde ins Stocken geraten. Das Ziel war, Nutzern die Wahl zu lassen, wie viel Kontrolle sie brauchten – ohne diese Wahl wie eine Last wirken zu lassen.
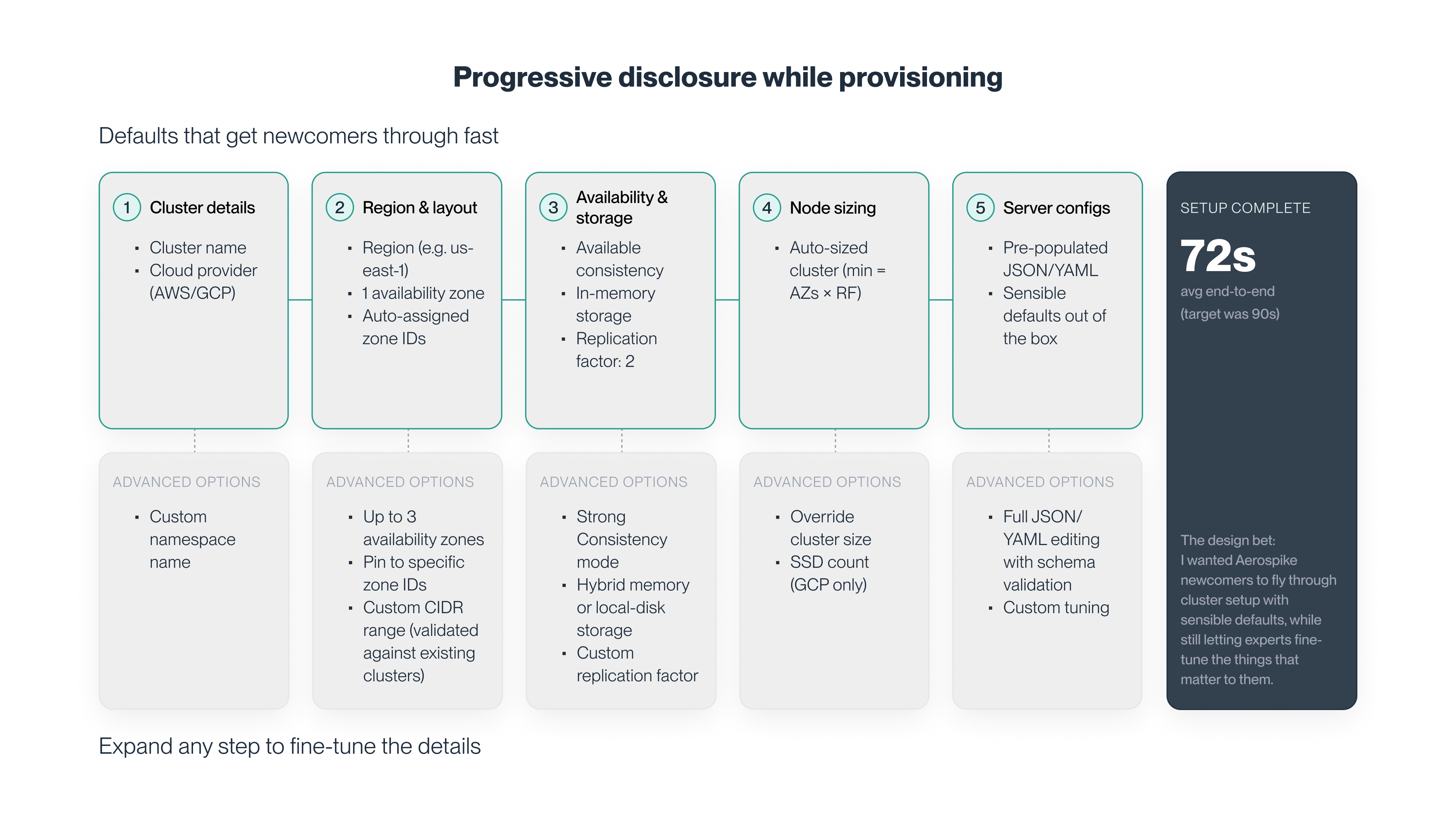
Design für sichere Geschwindigkeit
Standardwerte, die widerspiegeln, wie Aerospike wirklich funktioniert. Die Standardwerte waren keine generischen Cloud-Presets. Sie basierten auf Aerospike Best Practices und wurden mit Engineers validiert, die die Datenbank täglich betreiben und unterstützen. Wenn ein Nutzer jeden Standardwert akzeptierte, musste das Ergebnis etwas sein, hinter dem das Aerospike-Team steht.
Schrittweise Kontrolle ohne Bestrafung. Erweiterte Einstellungen waren verfügbar, ohne alle von Anfang an in den Expertenmodus zu zwingen. Für Nutzer, die volle Kontrolle wollten, war die JSON/YAML-Konfiguration bewusst zugänglich gemacht. Nicht versteckt, nicht vorgeschrieben. Und es war möglich, zwischen Modi zu wechseln, ohne den Flow neu zu starten oder den Kontext zu verlieren.
Leitplanken statt Überraschungen. Provisioning-Fehler können teuer sein. Im gesamten Flow wurden Einschränkungen und Validierungen entworfen, um ungültige oder riskante Konfigurationen vor dem Start zu verhindern. Wenn etwas falsch war, erklärten Fehlermeldungen explizit, was geändert werden musste und warum. Fehlerpfade erhielten genauso viel Designaufmerksamkeit wie Erfolgspfade.
Dokumentation als Teil des Systems. Kontextbezogene Hinweise erschienen neben Entscheidungen, stimmten mit der Sprache und dem Verhalten der UI überein und verstärkten dasselbe mentale Modell über UI, APIs und Dokumentation hinweg. Nutzer konnten lernen und Entscheidungen validieren, ohne das Produkt zu verlassen.
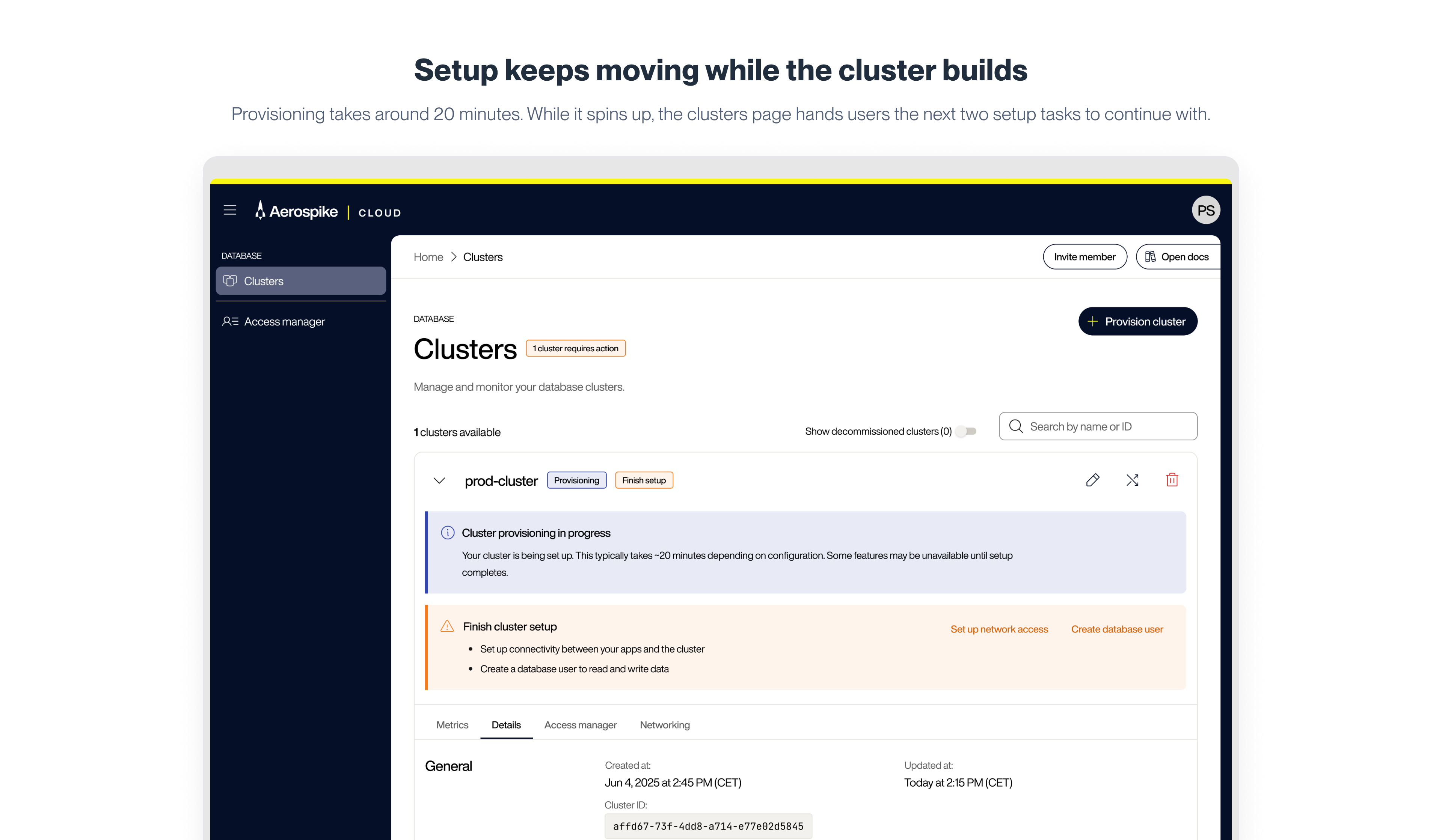
Weg zu den ersten Daten
Das Provisionieren eines Clusters dauert etwa 20 Minuten. Anstatt diese Zeit als Wartezeit zu behandeln, macht das Design sie nutzbar. Sobald ein Cluster gestartet ist, werden Nutzer sofort zu den zwei Aufgaben geleitet, die abgeschlossen sein müssen, bevor Daten fließen können: Netzwerkzugang einrichten und einen Datenbanknutzer erstellen. Beides ist verfügbar, bevor der Cluster live ist. Wenn das Provisioning abgeschlossen ist, haben die meisten Nutzer beides bereits erledigt.
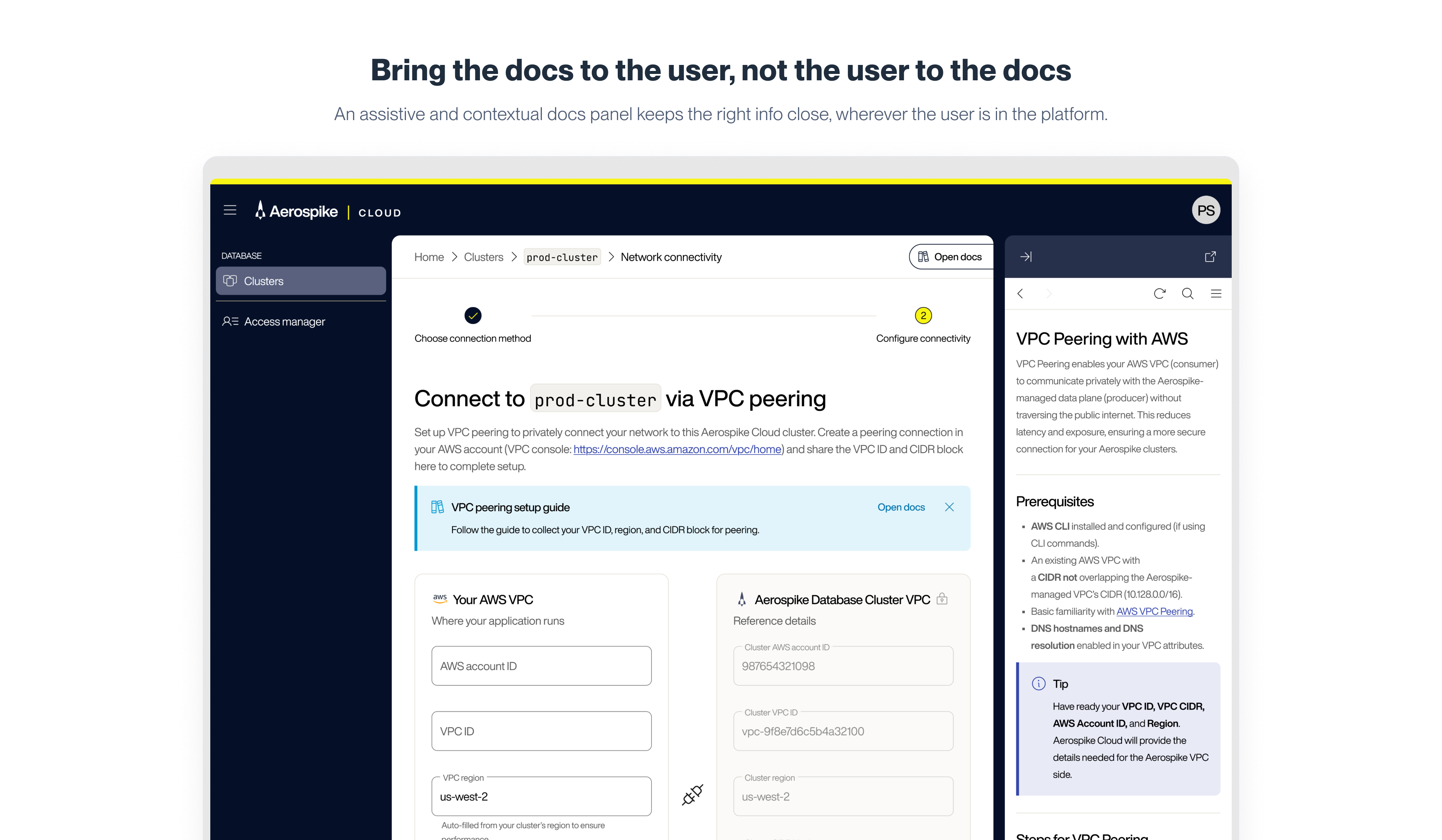
VPC Peering war der technisch anspruchsvollste Schritt in diesem Setup und das ungewöhnlichste Designproblem im gesamten Projekt. Eine Peering-Verbindung herzustellen erfordert Schritte in AWS, einer Umgebung, die Aerospike nicht kontrolliert. Nutzer müssen das Produkt verlassen, ihre AWS-Konsole aufrufen, bestimmte Werte sammeln, zurückkehren und das Formular ausfüllen. Das kontextbezogene Docs-Panel, das beim Provisioning als optionale Hilfe dient, wird an diesem Schritt zu etwas Wesentlicherem. Es öffnet sich mit einer Schritt-für-Schritt-Anleitung für genau diesen AWS-Workflow. Etwa jeder vierte Nutzer, der das VPC-Peering-Formular erreichte, öffnete das Panel, typischerweise nach einigen Minuten im Formular. Das legt nahe, dass das Layout die meisten Routinefälle abdeckte und das Panel für echte Komplexität zuständig war.
Die Erstellung von Datenbanknutzern war bewusst unkompliziert. Die wichtigste Entscheidung betraf das Passwort: Automatische Generierung war verfügbar, und das Passwort wurde einmal bei der Erstellung angezeigt. Ein CSV-Export ermöglichte die sichere Speicherung. Ein kleines Detail, aber eines, das zum Support-Problem wird, wenn es sorglos umgesetzt wird.
Ergebnis
Der Flow wurde als Grundlage für die allgemeine Verfügbarkeit von Aerospike Cloud geliefert. Die Abschlussrate durch den vollständigen Provisioning-Wizard lag weit über den Erwartungen für einen mehrstufigen technischen Konfigurationsflow. Der Schritt mit der höchsten durchschnittlichen Zeit war der erweiterte Konfigurationsschritt mit 24 Sekunden – beabsichtigt. Geschwindigkeit, wo es schnell sein soll. Tiefe, wo sie gebraucht wird.
Die durchschnittliche End-to-End-Provisioning-Zeit lag bei 72 Sekunden. Der Benchmark, den wir angestrebt hatten, war 90. Für Engineers, die einen Managed Service bewerten, ist das der Unterschied zwischen "Das könnte für uns funktionieren" und "Schauen wir uns weiter um."
Der Verlauf über die Zeit war das aufschlussreichste Signal. Validierungsfehler und Dokumentationsaufrufe beim Provisioning begannen beide hoch und sanken stetig, als das Erlebnis reifte – nicht weil die Nutzung zurückging, sondern weil die UI mehr selbst erklärte. Der Standard-Cluster-Pfad dominierte und bestätigte die zentrale Design-Wette: Standardwerte waren kein Fallback. Sie waren das primäre Erlebnis.
Das übergeordnete Ziel war ein Team, das vom ersten Klick über einen laufenden Cluster bis zur verbundenen Anwendung in einer einzigen Sitzung kommen konnte. Provisioning-Wizard, Setup-Hinweise und der Netzwerkzugangs-Flow waren alle auf dieses Ziel ausgerichtet.
Was ich mitnehme
Geschwindigkeit und Sicherheit erwiesen sich hier nicht als Gegensätze. Erfahrene Nutzer profitierten trotzdem sehr von klaren Standardwerten. Fehlerpfade und Wiederherstellung brauchten genauso viel Designzeit wie der Happy Path.
Das andere, was ich mitnehme: Dokumentation, APIs und UI müssen dieselbe Geschichte erzählen. Wenn nicht, verlieren Nutzer schnell das Vertrauen. Wenn doch, bewegen sich Menschen schneller als erwartet.
Für Engineers, die überlegen, ob sie einen Managed Service nutzen sollen, ist das Provisioning im Grunde die gesamte Präsentation. Falsch umgesetzt, und sie schauen sich anderswo um.
Das Feedback seit dem Launch war gut. Ich habe den Flow mit Wachstum im Hinterkopf gebaut, daher denke ich, dass die Grundlagen vorhanden sind. Aber jede neue Ergänzung wird ihre eigenen Fragen mitbringen. Preismodelle, andere Cloud-Anbieter, Backup-Optionen. Ob dieselben Prinzipien so weit tragen — das ist es, worauf ich mich freue, herauszufinden.
Lass uns reden
Etwas gefunden, das dich anspricht? Ich bin offen für die richtige Gelegenheit, eine Zusammenarbeit oder ein gutes Gespräch über Design.